

In this tutorial you’ll learn how to identify duplicate entries in a GIS dataset using ArcGIS Pro Python Notebooks.
If you want to use Python to find duplicate entries in a feature dataset, there are several ways to do so. This tutorial features two possible solutions. Both methods use the pandas and arcgis library. The second one uses a Counter object from the collections module.
Step 1: Download the data
We will use the Natural Earth quick start kit. In the tutorial covering bar charts using the matplotlib Python library, we found a feature that appeared twice in the attribute table, causing an outlier in the accompanying bar chart. First, download the data, unzip the file on your hard drive, open up Pro and create a new, empty project. Create a folder connection to the unzipped Natural Earth dataset and add the ne_110m_lakes.shp file (found in the “110m_physical” subfolder) to the map window so that it is listed in the maps contents pane on the right of the screen.
Step 2: Create a new Python notebook and import the libraries
Create a new Python notebook by selecting the Insert tab on the ribbon interface in Pro and select “New notebook”. A new notebook is opened. Use the following code to import the necessary libraries and create a spatially enabled dataframe of the feature set’s attribute table:
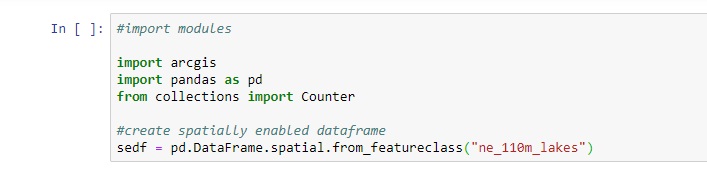
Step 3: Find duplicated rows based on a selected column
The pandas library Dataframe class provides a member function to find duplicate rows based on all or given column names only. We already know from earlier tutorials that there is one duplicate entry for this specific dataset, which is FID#19: a repeated entry named “Lake Onega”. We used Pro’s Find Identical tool to find this entry for us in an earlier tutorial, but we will now use Python’s pandas library to do this. Use the following code to find and list the duplicate row, which is indeed the feature with ID 19, as the output shows:
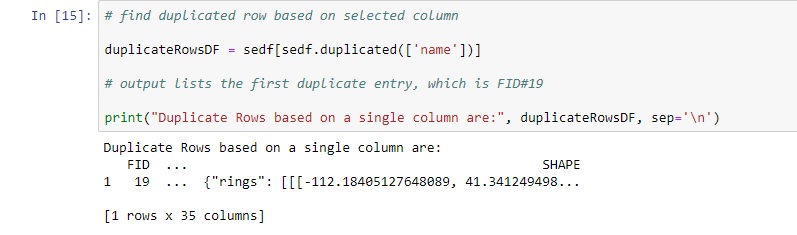
The output shows only the first and last column of the selected feature, but most importantly, it does more or less the same as Pro’s Find Identical tool. It does not list the first entry, only the second, repeated entry. However, this is enough to inspect the data and verify if there is a duplicate entry for this dataset.
Step 4: Identify duplicated field values using list objects
We’ll now show how you can identify repeated entries for a single column using Python list objects. It does exactly the same as the Dataframe.duplicated member function, but only using the column values which are converted to a list object and then counted individually. Note that this solution does not return feature IDs or entire rows: it only tells you if there are duplicate entries for a specified column. It is also a more involved way of finding duplicate values using more code, but it is nonetheless an approach that uses Python data types (lists), which are very useful in many cases. Use the following code to check for duplicated field values in the “name” column:
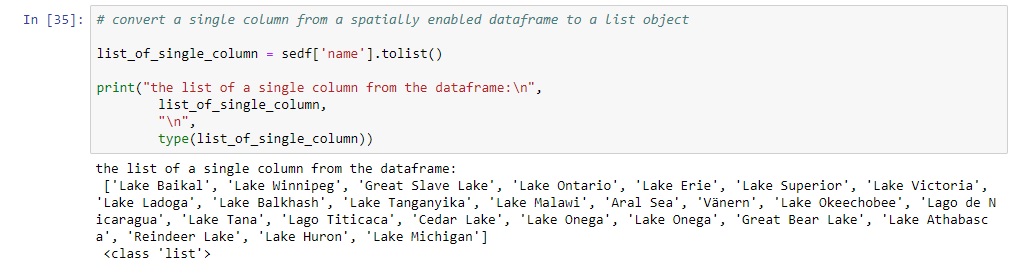
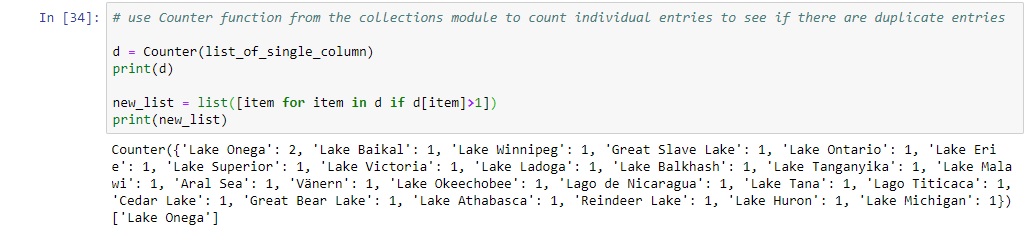
This code converts a column from a pandas dataframe to a list, including duplicates. This is possible as a spatially enabled dataframe is based on a pandas dataframe. In the output, you can see there two entries of Lake Onega. To count individual entries and check for duplicate entries, use a Counter object, as specified below. Make sure you import the collections module and Counter object, as specified above:
Learn more about using Python in ArcGIS Pro in our Introduction to Programming ArcGIS Pro with Python and Intermediate ArcGIS Pro Programming with Python classes.
