
In this tutorial, we’ll explain how you can find identical features (also known as duplicate data) in a feature dataset.
Step 1: Download the data
We will use the Natural Earth quick start kit. In the tutorial covering bar charts using the matplotlib Python library, we found a feature that appeared twice in the attribute table, causing an outlier in the accompanying bar chart. Duplicate entries often appear in a dataset and are often errors that need to be inspected before using the data for analysis. If a duplicate is found, and is verified to be a duplicate entry after checking all individual field values to be the same, it is often deleted.
We’ll have a look at how to identify such features using Pro’s Find Identical tool. First, download the data, unzip the file on your hard drive, open up Pro and create a new, empty project. Create a folder connection to the unzipped Natural Earth dataset and add the ne_110m_lakes.shp file (found in the 110m_physical subfolder) to the map window so that it is listed in the maps contents pane on the right of the screen.
Step 2: Inspect the data and locate the duplicate entry
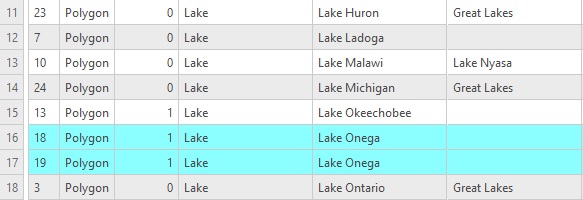
Before we use Pro to identify the duplicate entry for us, we’ll first locate it by simply opening the attribute table and inspect the data ourselves. Right-click the ne_110m_lakes layer in the contents pane on the left of the screen and select “attribute table”. Right-click the “name” column heading and select “sort ascending”, so that the lake names are listed alphabetically. The duplicate entry is named “Lake Onega”: it appears twice in the dataset. Both are selected in the image below in green. Notice the feature IDs of both identical features, 18 and 19:
Step 3: Use the Find Identical geoprocessing tool to find the duplicate values
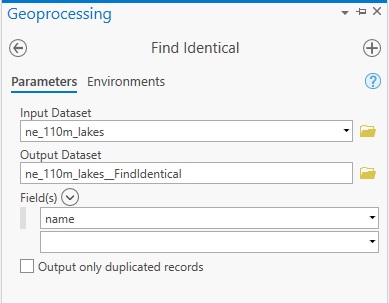
Pro has a tool that automates the process of step 2. The Find Identical geoprocessing tool lets you select one or multiple fields (column names) and compares all field values. The tool returns a table with three columns: the ObjectID belonging to this particular table, the IN_FID field, that uses the FID values from the original attribute table and can be used to join the records of the output table back to the input dataset if necessary. The third field is named FEAT_SEQ, that lists identical records with duplicate numbers. The tool is found under Data Management tools -> General -> Find Identical. Find and run the tool using the following parameters:
Step 4: Inspect the resulting standalone table
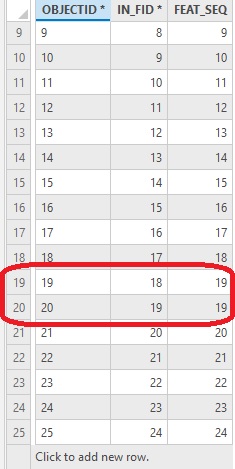
The tool produces a standalone table with containing three fields, that is added to the contents pane at the bottom. Locate and open the table. Looking at the image below, you can see that Feature IDs 19 and 20 share the same FEAT_SEQ field value, 19. This means that there’s a duplicate entry based on the “name” field values, just as we have seen in step 2:
Step 5: Run the same tool, now only showing identical records
To show only the duplicated records instead of all entries, run the tool again using the same parameters as under step 4, but mark the checkbox “Output only duplicated records”. This will show the following table:
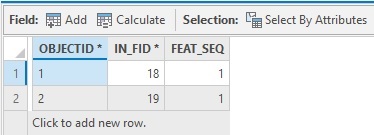
There are only two records: the two identical records, with the original FID listed in the “IN_FID *” column.
