
Using arcpy’s SearchCursor for selecting and returning records
In this tutorial, we willl be using arcpy’s SearchCursor class for returning records from a feature class.
Arcpy’s Data Access module provides the SearchCursor class, from which cursor objects can be created to return records from a feature class or table. You can think of a SearchCursor as an iterator as used in a for or while loop, that returns new data with each iteration. In this tutorial, we will show how you can create SearchCursor objects that return column data from a feature class. To follow along, create a new notebook inside ArcGIS Pro and run the code snippets below with a feature class of your choice. Here, we’ll be using a Feature Service Feature Class downloaded from ArcGIS Online called “Hospitals_England”, which contains a point layer for all hospitals in the UK and needs to be added to the map first by dragging it from the Catalog pane to the map window inside Pro.
Retrieve column data using a SearchCursor
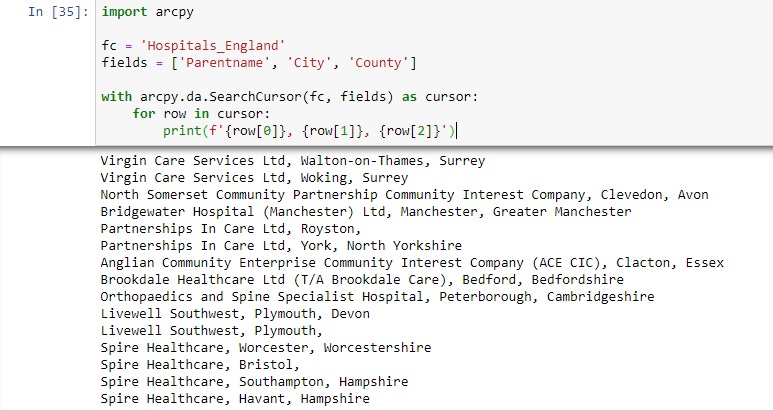
To start working with SearchCursors, it’s important to understand their syntax, which is specified here. SearchCursors only take two required parameters: a table or feature class name, followed by one or multiple field names (= column names) that need to be returned by the SearchCursor object. This code snippet listed below shows how to return three different columns from the attribute table data from our Hospitals_England file: the ParentName, City and County columns.
Note that the three column names are stored in a list variable named ‘fields’, that is referenced when calling the SearchCursor method in line 4. Using an f-string to print the individual field values for each column in line 6, we reference each column using an index, starting from zero. The SearchCursor prints a tuple for each row of the attribute table containing the field values for the three specified columns. Note that you can specify as many columns as necessary inside the fields variable. You could, if necessary, change the order of the different column names inside the fields value, but will result in performance issues.
import arcpy
fc = ‘Hospitals_England’
fields = [‘Parentname’, ‘City’, ‘County’]
with arcpy.da.SearchCursor(fc, fields) as cursor:
for row in cursor:
print(f'{row[0]}, {row[1]}, {row[2]}’)
Here’s the code with a snippet of the output:
Limiting your SearchCursor’s output
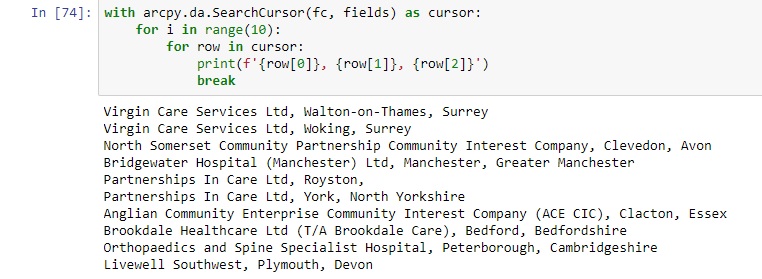
The code snippet above returned the three specified column values for more than 1,000 rows. For attribute files with many rows, this can be inefficient. If you want to limit your output to, say, the first ten entries only, you can extend the code from step 1 with a nested loop using a range value and a break statement, as shown in the code snipped below. Running this code will only show the first ten entries, instead of more than 1,000 as before:
with arcpy.da.SearchCursor(fc, fields) as cursor:
for i in range(10):
for row in cursor:
print(f'{row[0]}, {row[1]}, {row[2]}’)
break
Here’s the code snippet and the output:
Returning and counting individual field values per column
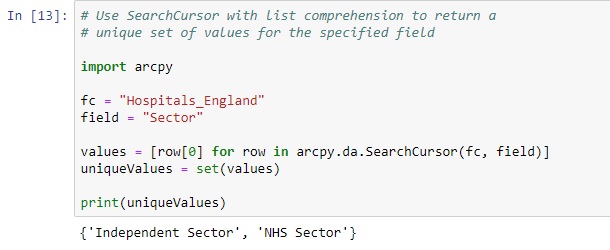
A SearchCursor can also be used to return all unique values in a column. Rather than returning all individual items per row, and printing hundreds of duplicate values, you can use a SearchCursor to print them only once. Consider the following list comprehension in line 4 that is stored in the ‘values’ variable, to be used for returning a set data structure that contains all unique column items only once. In this case, we are interested in the different field values in the ParentName column. There are only two unique values, as shown below in the output:
import arcpy
fc = “Hospitals_England”
field = “Sector”
values = [row[0] for row in arcpy.da.SearchCursor(fc, field)]
uniqueValues = set(values)
print(uniqueValues)
Output: {‘Independent Sector’, ‘NHS Sector’}
Here’s the code snippet and output:
Taking this example one step further, it would be nice if Python could tell us how many entries there are for each hospital type. This can be done using the (builtin) collection module’s Counter class and passing in the values list comprehension, as displayed below. Remember that the ‘values’ valuable contains all instances (rows) of both hospital types. These are counted by category and returned by Python as a Counter object, which is a tuple containing a dictionary:
from collections import Counter
Counter(values)
Output: Counter({‘NHS Sector’: 713, ‘Independent Sector’: 407})
Here’s the code snippet and output:

